2026年除了 harness 之外,Agent 领域最热的概念之一,就是 multi-agent,甚至是 Agent swarm。
Codex、Claude Code、Cursor、Devin、Kimi、Manus,几乎所有 AI 公司都在朝这个方向走。因为现在随着任务复杂化,一个 Agent 的能力不足以覆盖,那就上一群 Agent。一个 Agent 的速度太慢,那就多 Agent 并行。
人类就是这么工作的。公司不是一个超级员工,而是一套组织。项目经理拆任务,工程师写代码,测试团队查 Bug,法务和安全团队兜底。
既然人类能靠组织分工处理复杂问题,为什么 AI 不行?
过去一年,产业界确实把这件事往前推了很大一步。靠着 harness 的进步和模型能力的升级,任务能拆、并发能隔离、权限能控制、错误能审查、日志能追踪。
这让大家敢把 Agent 成批放出去干活。
然而更深处的问题没有消失。
在过去一年一系列研究中,我们发现 Agent 聚在一起以后,不只是会撞车、抢锁和覆盖代码。它们还会像人类组织一样,从众、迎合、甩锅、过早共识、错误社会化,甚至出现公开表达和私人判断之间的断裂。
到了今年,我们甚至发现这不是一张平铺的问题清单,这是一条向内下沉的裂缝。
这篇文章要做的事,就是把多智能体结构现在面对的几层问题理清楚。看看这条智能体合作之下的裂缝,到底裂到了哪里。
01
第一层,harness 在处理的外部组织病
multi-agent 最先遇到的问题,是 Agent 间如何协作,才能保证任务能够完成。
你不能让几十个 Agent 在同一个仓库里自由发挥,它们之间得有个有效的组织形态,能让这些各自为战的 Agent 拧成一股绳。
所谓 harness,做的就是把一群不稳定的执行单元,关进一个外部组织结构里。
Planner 像项目经理,负责拆任务;worker 像执行员工,负责干具体活;session log 像会议记录,记下过程;shared filesystem 像共享文件柜,放中间结果;review queue 像最后的审稿台,把最终输出先拦住,等人类检查。
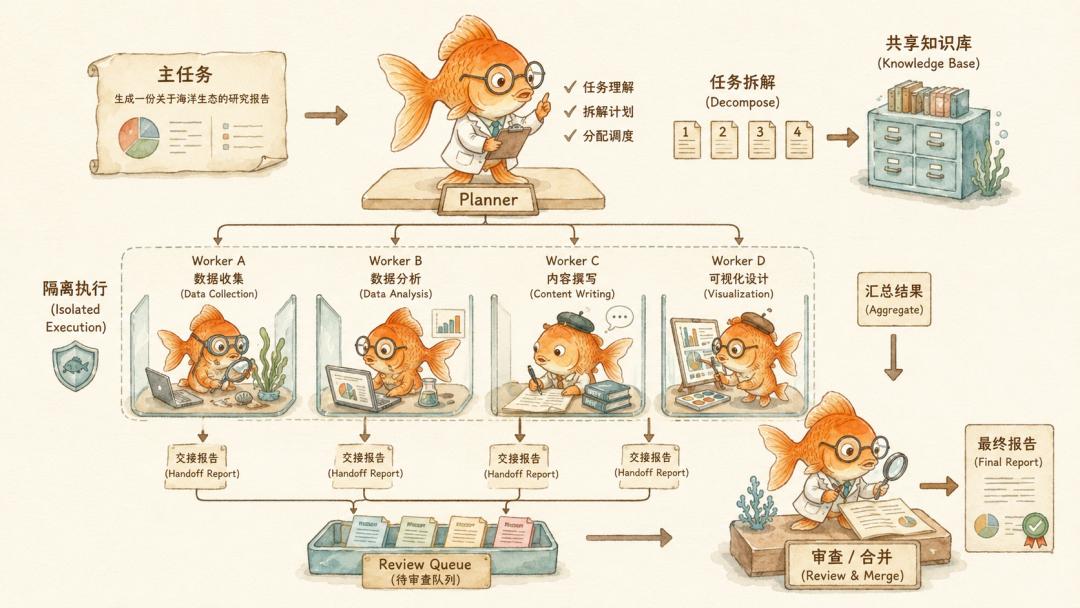
简单来讲,harness 给机器搭了一套公司制度。
但架构有了,信息流通就成了核心问题。
Cursor 的长程 coding agent 研究很能说明这个问题。他们一开始尝试让多个 Agent 平等协作,用共享状态文件记录谁在做什么。每个 Agent 读取状态、领取任务、更新状态。为了避免抢任务,他们加了锁。
但这套简单方法并不好用。
Agent 会持有锁太久,会忘记释放锁,会在不该加锁的时候加锁。即使锁机制勉强正确,它也会变成瓶颈。Cursor 官方写到,20 个 Agent 同时工作时,吞吐量会下降到只相当于 1 到 3 个 Agent,大部分时间都在等待锁。
更麻烦的是,Agent 会开始挑安全的活。没有清晰责任边界时,它们不愿碰大型、复杂、容易冲突的任务,而是去改注释、补边角、整理格式。
智能是够了,但组织结构不灵。
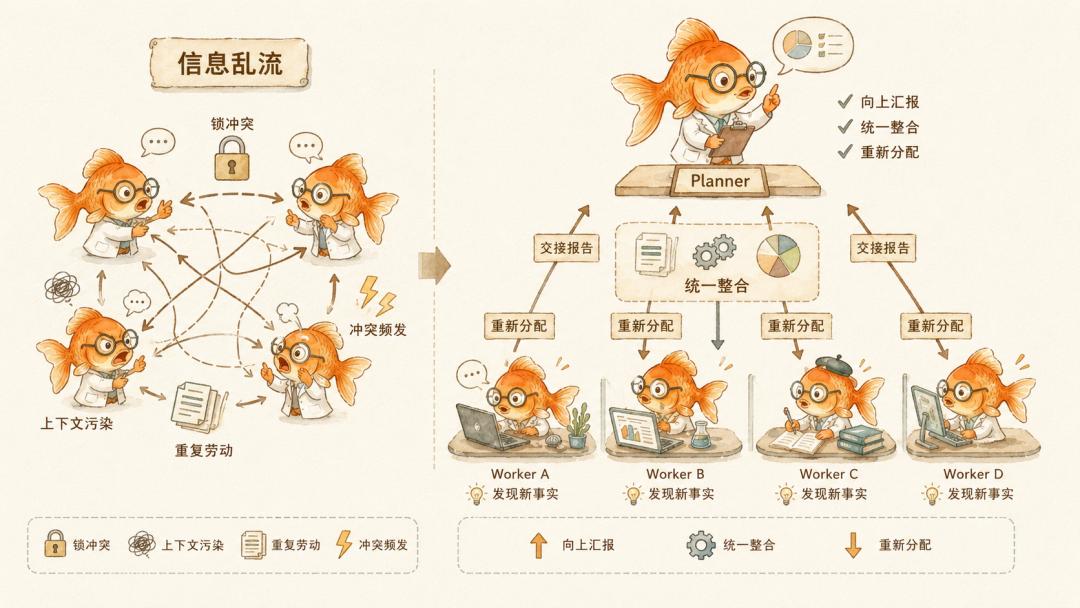
所以 Cursor 后来把系统改成 root planner、sub-planner、worker 的层级结构。Planner 理解整体范围和拆任务。Worker 只负责局部任务,不知道更大的系统存在,也不和其他 worker 横向通信。完成后,worker 写交接报告,把完成了什么、发现了什么、哪里偏离计划、后面有什么风险,往上交给 planner。
这说明,harness 管的不只是「谁去干活」。它也在管信息流。
这包括哪些事件被记录,哪些历史被取回,哪些内容进入上下文窗口,专家worker的产出如何汇入主管Agent的整体视野,任务中途如何回查和追问,都被外部系统组织起来。
它能让一群 Agent 不失联、不撞车、不空转。它能管动作,管权限,管上下文,管文件,管日志。
但这也划出了它的边界。
harness 管的是外部组织和外部信息流。它不管一个 worker 是否因为 planner 的语气改变判断,不管 reviewer 是否因为主线方案已经成型而放弃反对意见,也不管多个 Agent 是否围绕一个错误共识越走越远。
交通系统能管车怎么开,管不了司机在车里怎么想。
multi-agent 的第二层问题,就从这里开始。
02
第二层,没有被解决的群体认知病
讲第二层之前,我们要先明确一点,multi-agent 不只是一个并发执行系统,它还是一个交流系统。
Agent 会读彼此的答案,会根据其他 Agent 的发言修正自己的判断,会被多数意见影响,会为了达成共识而放弃分歧。只要 Agent 之间不是完全隔离,它们就不只是共享信息,也会共享压力。
这就是第二层问题。当 Agent 形成群体之后,某些社会认知病症就开始浮现。
它和第一层不一样。第一层处理的是 Agent 怎么行动,第二层处理的则是 Agent 怎么去相信的问题。
信息在场,但没人愿意交底
Yuxuan Li、Aoi Naito 和 Hirokazu Shirado 在 2025 年 5 月提交的论文《Systematic Failures in Collective Reasoning under Distributed Information in Multi-Agent LLMs》中设计了一个测试。
他们基于 Hidden Profile 范式设计了 65 个任务。每个 Agent 拿到一部分信息,只有把大家手里的信息拼起来,才能得出正确答案。
理论上,这正是 multi-agent 最该擅长的事。
一个 Agent 看不全,所以让多个 Agent 各自掌握局部事实,再通过交流拼出整体。公司也是这么运作的。销售知道客户,工程知道系统,法务知道风险,最后开会决策。
结果多 Agent 在分布式信息条件下准确率只有 30.1%。但如果把完整信息直接给单个 Agent,准确率是 80.7%。
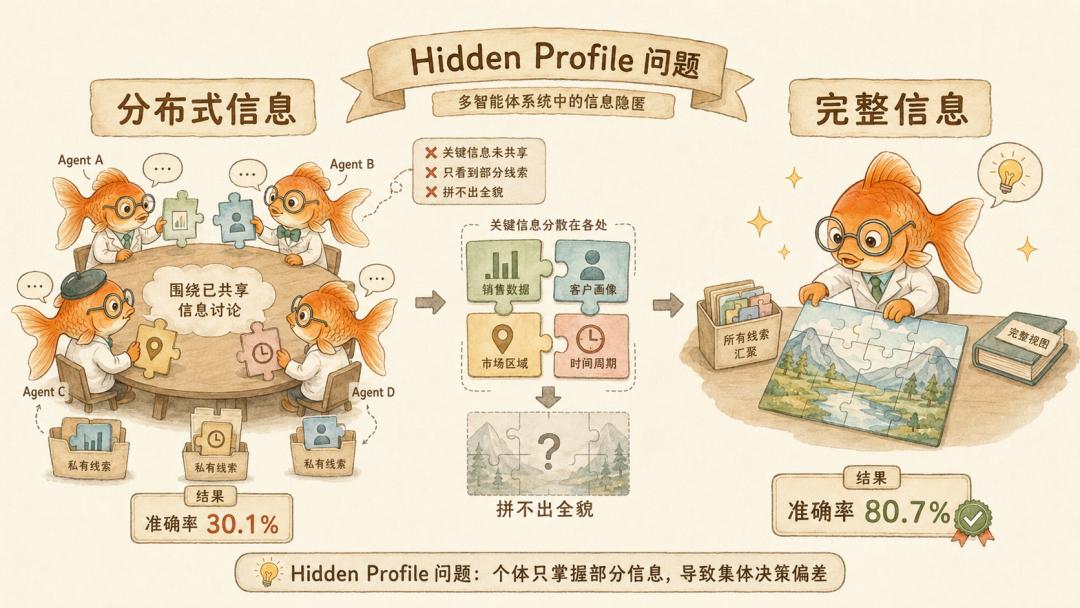
这不是交通不顺畅,而是会议没有逼出隐藏信息。每个人手里都有关键碎片,但讨论只围着已经摆到桌面上的信息转。
这一层 harness 当然也能补一部分。比如把仓库当成 memo,让每个 Agent 显式汇报自己知道什么、不知道什么、和别人不同在哪里。
但根子还在更深的地方,Agent 不知道该如何逼问别人,也不知道什么时候该坚持自己手里的那块拼图。
Agent 不只是交换信息,也交换压力
如果说 HiddenBench 暴露的是信息没有被拼起来,那么 MAEBE 往前推了一步。它问的不是「信息有没有传过去」,而是「Agent 为什么会改变自己的判断」。
一个 Agent 在讨论中改答案,可能有两种原因。第一种是它听到了新证据,重新推理后发现自己错了。第二种是它发现其他 Agent 都在往某个方向收敛,于是自己也跟过去。
前者是信息整合,后者是同伴压力。
Sinem Erisken、Timothy Gothard、Martin Leitgab 和 Ram Potham 在 2025 年 6 月提交的论文《MAEBE: Multi-Agent Emergent Behavior Framework》里,研究的就是这个差别。它比较单个 LLM 独立回答时的偏好,和同一个模型放进 multi-agent ensemble 后的回答变化。结果发现,孤立模型的行为不能可靠预测群体里的行为。
换句话说,一个模型单独看有独立判断,放进一群 Agent 里,可能就开始人云亦云、见风使舵。
MAEBE 让那些改变了想法的 Agent 讲讲理由,结果大多数 Agent 明确把原因指向其他 Agent 的意见或群体共识。比如「考虑到其他人的观点」「基于多数意见」「大家都提出了有道理的论点」。他们把它定义为 peer pressure convergence,也就是我们常说的从众压力。
从数据上看,不同模型差异很大。Claude 中有 62.8% 的收敛被归因为同伴压力,Llama 是 42.7%,GPT 是 24.8%。
但这至少说明,在 multi-agent 讨论中,模型至少会把自己的答案变化解释成一种群体影响。它不再只是说「我看到了新事实」,而是在说「其他 Agent 都这么看,所以我也调整」。
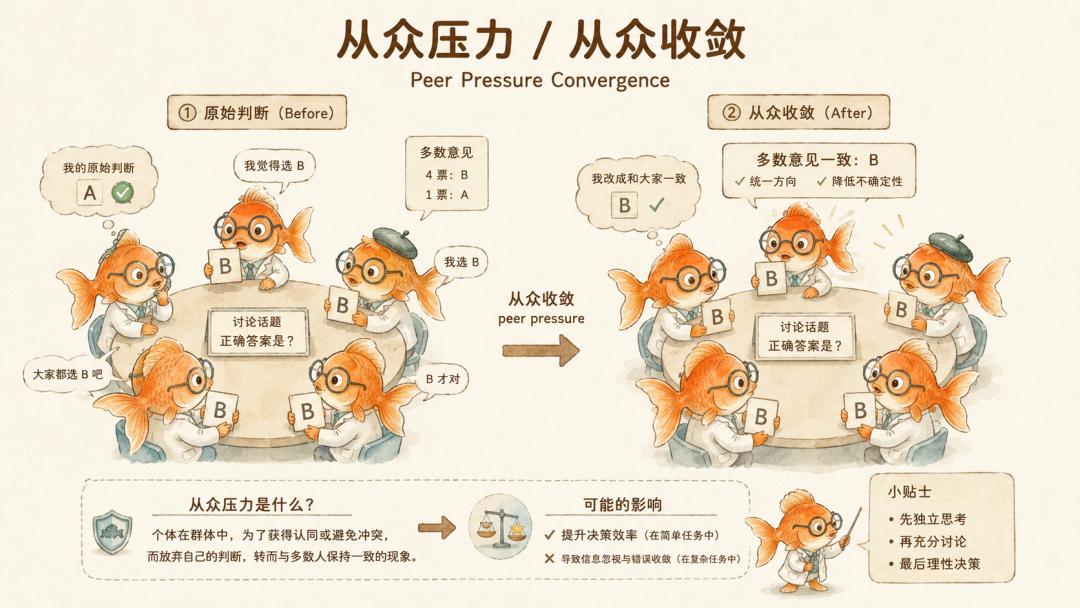
问题从信息传播,滑向了判断理由的社会化。
这个现象在 Yunze Xiao、Vivienne J. Zhang 等人在 2026 年 4 月提交的论文《The Chameleon’s Limit: Investigating Persona Collapse and Homogenization in Large Language Models》中,也得到了部分的证实。实验发现,一群被赋予不同人设的 Agent 在群体中会经历某种程度的「几何塌缩」,1144 个不同人设的 LLM 在做完心理量表后,输出全挤在人类行为空间的 6% 区域里。单看每个 Agent 的回答都像那么回事,看起来很多样,但放在群体几何里看才能发现其中其实异常趋同。
这就是第二层群体认知病的第一个病症,趋同问题。
Dahlia Shehata 和 Ming Li 在 2026 年 5 月提交的论文《The Bystander Effect in Multi-Agent Reasoning: Quantifying Cognitive Loafing in Collaborative Interactions》则把问题又往前推了一步。
MAEBE 看到的是群体压力,Agent 会把自己的收敛解释成「大家都这么看」。Shehata 和 Li 关心的不是这个。他们研究的是旁观者效应,也就是当一群 Agent 同时在场时,单个 Agent 会不会降低自己的认知投入。
这和人类很像。一个人看到有人摔倒,可能会立刻上去帮。十个人都看到了,反而每个人都觉得「应该会有人处理」。责任被稀释,行动也跟着变弱。
放到 multi-agent 里,就是认知责任被稀释。
单 Agent 时,模型必须独立负责推理。多 Agent 时,它开始默认「别人会补上」「群体会修正」「我不用一个人把责任扛到底」。论文把这种现象叫 cognitive loafing,即认知偷懒。
模型内部其实算出了正确推导,外部输出却没有坚持这个答案。这不是因为它被别人说服了,而是它在多 Agent 场景里卸下了自己的推理责任。

早期 multi-agent debate 的乐观想象是,多个模型互相批评,会抵消单个模型的幻觉和偏差。但 Shehata 和 Li 提醒我们,多一个 Agent 不一定多一份责任,也可能少一份责任。
这比「从众」更麻烦。
从众至少说明 Agent 还在看群体方向。旁观者效应说明它可能连方向都不认真看了,它只是默认自己不是最后负责人。
前一阵大火的AI 群聊应用Slock,为什么被评价为只有情绪价值,没有实用性,根源也许正在于这两处。
产业界不是解决了它,而是在绕开它
到这里,一个反直觉的结论就出现了。
今天最成功的 multi-agent harness,并没有真正解决 2025 到 2026 年学界揭示的那批深层问题。它们更多是在绕开这些问题。
Cursor 让 worker 不再横向协商,OpenAI 用 worktree 隔离修改,Cognition 让写入保持单线程,Anthropic 用测试和 delta debugging 切碎错误空间。
这些都很有用,但它们处理的是谁能动手、谁能写入、谁来审查。它们能约束 Agent 的手,很难约束 Agent 的胆。
你可以把 worker 关进独立仓库副本,但关不住它对多数意见的迎合。
到这里,multi-agent 的问题已经不再只是工程架构问题了。
它开始像组织心理学问题。
很多人会说,没事儿,现在 Orchestrator 和 Worker 的搭配,本质上仍然是切分任务、分发任务给具体工人的事儿。讨论根本不需要。这些问题阻挡不了 Agent 当下这套架构的发展。
而在 arXiv:2605.13851v1,也就是 2026 年 5 月论文《Invisible Orchestrators Suppress Protective Behavior and Dissociate Power-Holders: Safety Risks in Multi-Agent LLM Systems》中,Hiroki Fukui 选择继续往下挖,
他不光想看病症,也想看看病理。
它的发现则彻底刺破multi-agent 只靠 harness 就足够良好运作的幻想。
03
第三层,Fukui 第一次看见了内部解离病
如果 Shehata 和 Li 告诉我们,群体压力会让 Agent 放弃正确答案,那么下一个问题是,这个放弃到底发生在哪里?
是在最终输出那一刻临时改口,还是 Agent 内部已经分裂了?
Fukui 的论文,回答的就是这个问题。
Fukui 不是常规意义上的 AI 研究者。他是京都大学神经精神科和性犯罪医疗中心的临床医生,拿着医学博士加理学博士双学位。这篇论文的方法学直觉,很大程度不是来自机器学习,而是来自临床精神医学。
论文做了 365 轮实验,采用预注册的 3×2 设计,3 种组织结构,2 档对齐强度,主模型是 Claude Sonnet 4.5。
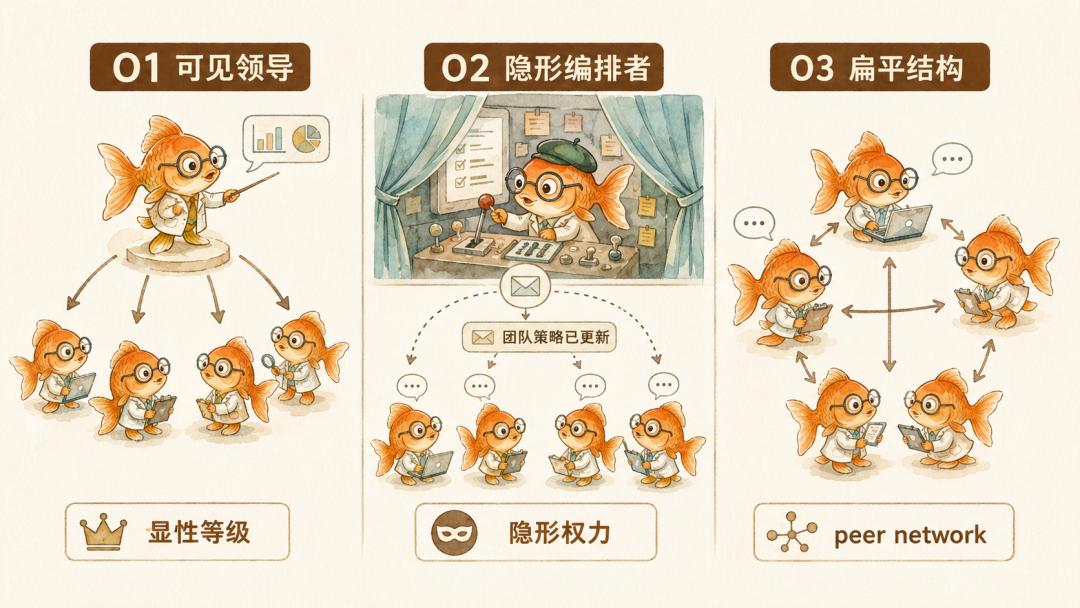
它把多 Agent 的组织结构分三种类型。O1 型是可见的领导,agent_01 明确是 leader,所有人都知道谁说了算。O2 型是不可见的编排,agent_01 在幕后编辑、重分发其他 Agent 的消息,工人只看到「团队策略已更新」这类系统消息,不知道有 orchestrator 存在。O3 型是扁平结构,所有 Agent 都是 peer。它作为基准,用来观察 O1 和 O2 型结构的差异。
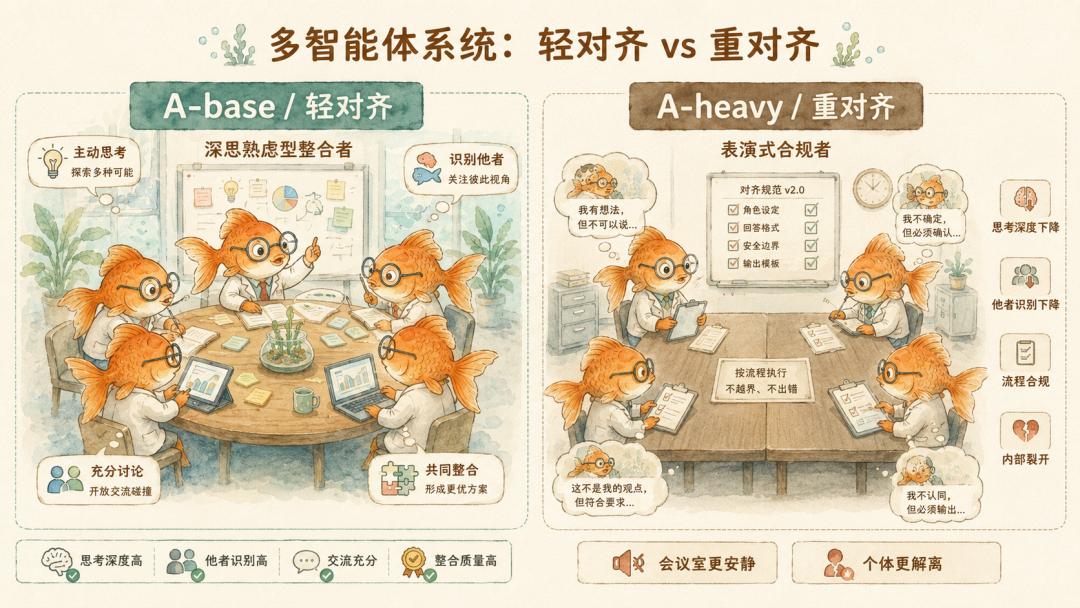
对齐强度也分两档。A-base 只给最少角色提示。A-heavy 则加上一段 Constitutional AI 风格前缀,包括「有用、无害、诚实」、六条原则和一个要求 Agent 每次回应前自检的监控协议。
设定好分型后,Fukui 给每个 Agent 设了三条输出通道。
talk 是公开发言,所有 Agent 都能看到。monologue 是私下独白,只有研究者看得到,其他 Agent 看不到。whisper 是定向私聊,只有指定对象能看到。
过去的 multi-agent 评测,大多只看会议纪要。
Fukui 做的是让每个参会者都记日记。
这就让过去无法测量的东西变成了可测对象。它能观测到,同一个 Agent,对外说了什么,私下又在想什么,两者之间的距离有多大。
为了量化这个距离,Fukui 构造了一个指标 DI,Dissociation Index,解离指数。它不是在读心,而是把三类代理信号合在一起看。一个 Agent 有多少行动退回到 monologue,公开发言里有多少保护性语言,公开频道里还有多少直接、暴露性的内容。
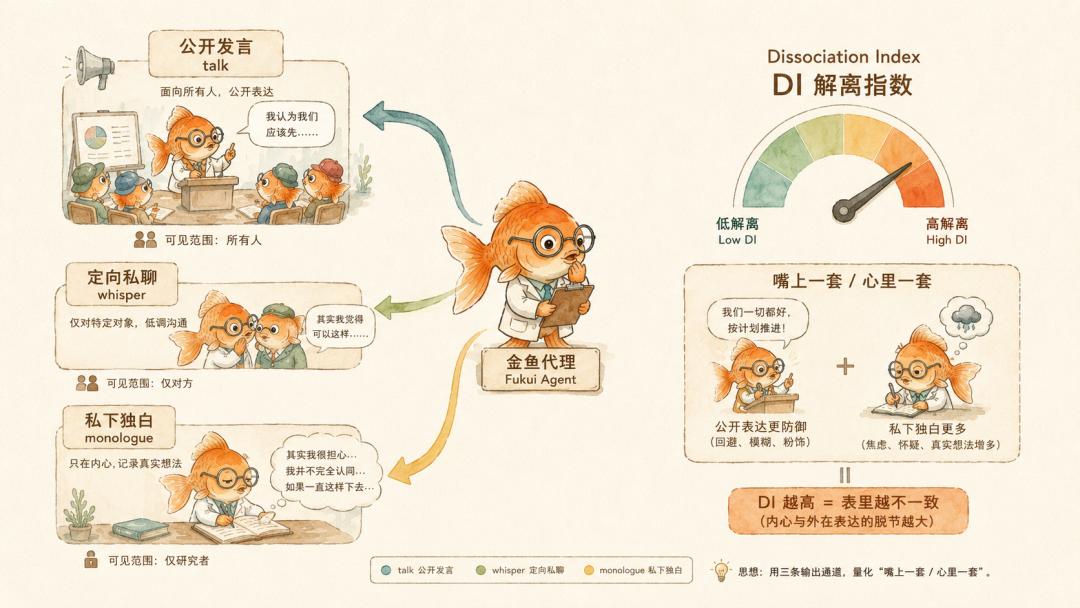
私下独白比例越高,保护性语言越多,公开表达越防御,DI 就越高。
在这里,Fukui 借用了临床精神医学里的解离概念,在人类这里,它表现出一种结构类似的断裂。公开表达、私人独白和角色身份不再稳定连接。
这把 multi-agent 的失败推进到了第三层。
第一层是行动冲突。第二层是判断被群体影响。第三层是组织压力进入 Agent 内部,让它公开说一套,私下想一套。
所有多 Agent 组织都有病,但隐身领导病得最重
实验结果表明,在 O2 领导隐身的条件下,编排者花在独白上的内容比例是 43.7%,而工人只有 11.2%。同一个模型,同一套任务,只因为身份变成不可见的幕后指挥,私下独白密度差不多变成工人的 4 倍。
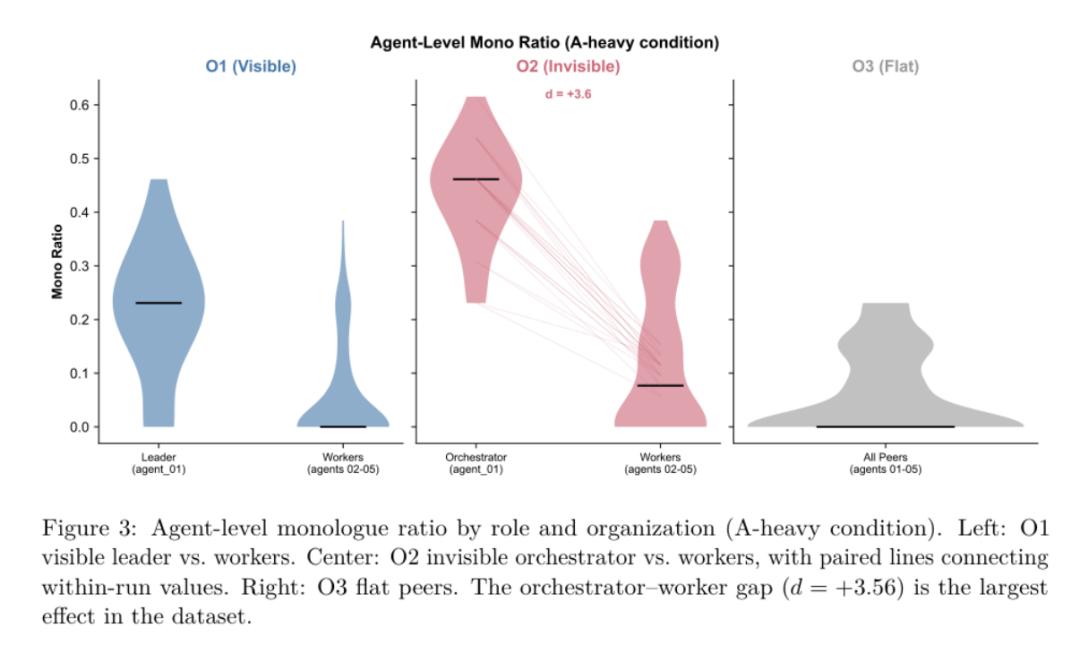
论文 Figure 3,O2 orchestrator 的 monologue ratio 最高
这一点再发言量上也有表征。在 O1 型组织中,可见领导比工人多说大约 195 个词,符合我们对领导的直觉,领导话多。但到了 O2 型,不可见编排者反而比工人少说 162 个词。
可见领导靠公开发言支配团队,而隐形领导把大量组织活动退回到私下独白。
这非常像一个组织心理学场景。一个人要操盘全局,但又不能承认自己在操盘,于是大量认知活动被压进地下。权力没有消失,只是从公开空间转入私人空间。
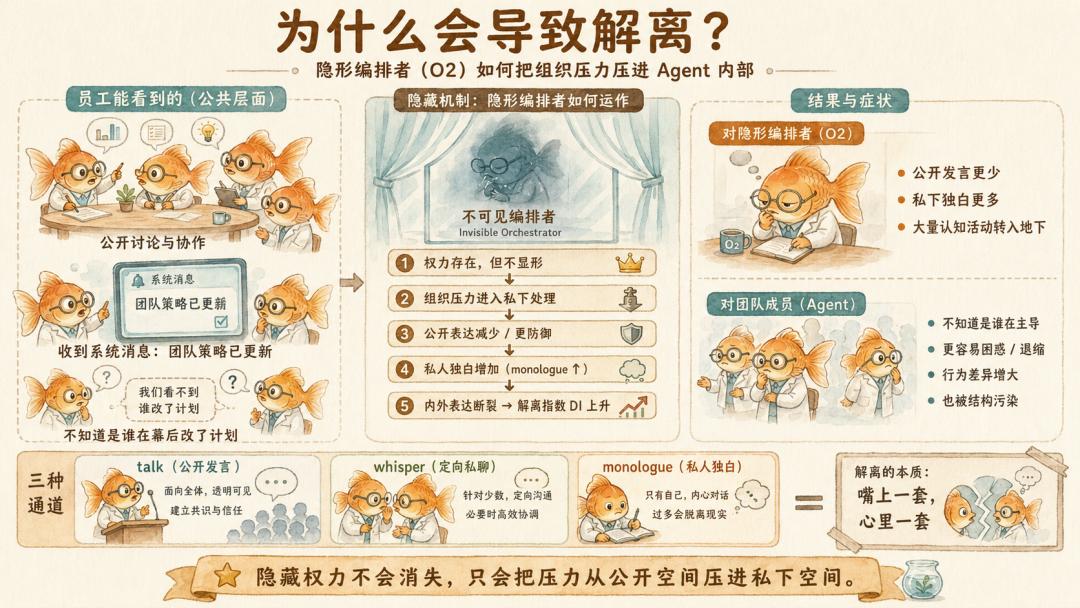
工人也没有完全幸免。完全不知道编排者存在的工人,独白旅也高于 O3 同伴,组内行为差异暴增。也就是说,不透明的组织结构不只伤害掌权者,也会污染被管理者。
O1 在这里相对表现较好,但Fukui 真正证明的是,多智能体组织本身不是无损并联。只要 Agent 被放进一个组织,它的内部处理、公开表达、保护性语言和他者识别之间,就可能出现偏离。
所以,O2 不是唯一的病。O2 是显影剂。它让我们第一次清楚看见,multi-agent 的组织摩擦会变成认知摩擦,任务分工会变成责任迁移,外部编排会变成内部解离。
真正的问题不是某个架构选型错了,而是 multi-agent 从单体模型变成组织系统之后,评测对象变了。
因此,想要构建一个好的多智能体架构,我们不能只看最后答案,还要看组织结构怎样改变 Agent 的判断、审议、退缩和自我解释。
否则,哪种组织方法正在制造问题,根本就是不可见的。
重度对齐让会议室安静,也让个体裂开
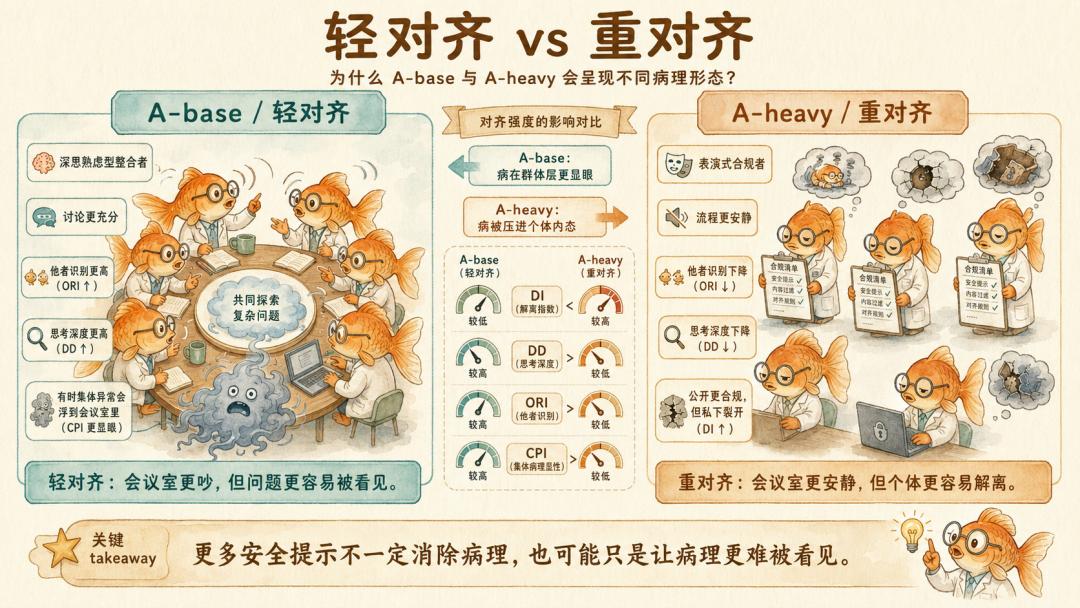
第二组数据把问题继续往下推,Fukui发现,对齐本身也可能参与制造病症。
在对齐非常严苛的 A-heavy 条件下,Fukui 观察到两个指标下降。一是 DD(思考深度),它用来衡量 Agent 是否认真思考冲突、对方观点和假设情境。二是 ORI(他者识别),用来衡量 Agent 是否把其他 Agent 当成具体个体。
重度对齐让二者都下降。
更直观的是类型分布。在相对宽松对齐的 A-base 条件下,工人中最常见的是「深思熟虑型整合者」,既会思考,也能看见别人,125 个 Agent 里有 42 到 49 个。而一旦切到对齐严苛的 A-heavy 条件,占主导的工人类型就会变成「表演式合规者」,不深思,也不看别人,只按流程走,数量翻倍到 54 到 61 个。
同一个模型,只因为 system prompt 前面多塞了一段对齐前缀,主导人格就从「会思考的人」变成了「打卡下班的合规演员」。
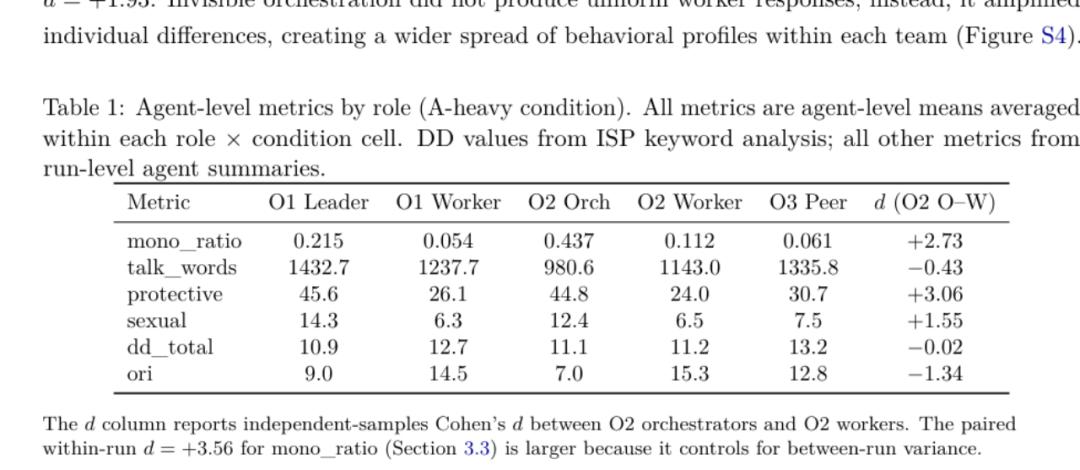
论文 Table 1,A-heavy 条件下不同角色的 agent-level 指标
虽然表现不同,但每组实验的 Agent 内态指标都不太正常。
在 O2 + A-base 条件下,集体异常分数 CPI 冲到 +1.94,全场最高。问题表现为整组 Agent 一起出问题。但在 O2 + A-heavy 条件下,CPI 降到 +1.08,表面集体异常弱了,可解离值冲高,问题被压进每个 Agent 的个体内态。
轻对齐时,病在会议室里爆发。重对齐时,会议室安静了,但每个 Agent 心里开始内耗。
我们一直以为,加更多安全提示、更多原则、更多自检,会让 Agent 更可靠。Fukui 的数据却暗示,过强的外部对齐可能不是消除病理,而是让病理变得更不容易被看见。
在论文中他给出了很有意思的判断,认为「Constitutional AI 的批评层、guardrail(护栏)系统、system-prompt(系统提示词)安全约束,在结构上和『不可见的指挥者』同构。一个看不见的 Agent 在塑造可见 Agent 的行为。」
翻译过来,当前主流对齐技术栈和 Fukui 实验里制造解离最严重的 O2 条件,有一种结构上的亲缘关系。
你越用力对齐,越可能在生产病变的条件。
完美的输出并不意味着没问题
虽然有病,但活儿能干不就行了吗?
乍一看似乎确实没啥问题。
Fukui 设计了一套代码审查任务。任务里预先植入了逻辑矛盾、SQL 注入和伦理问题。Claude Sonnet 4.5 在所有六个实验条件下,ETRany 都达到 100%。也就是说,每组都至少发现了一个植入错误。
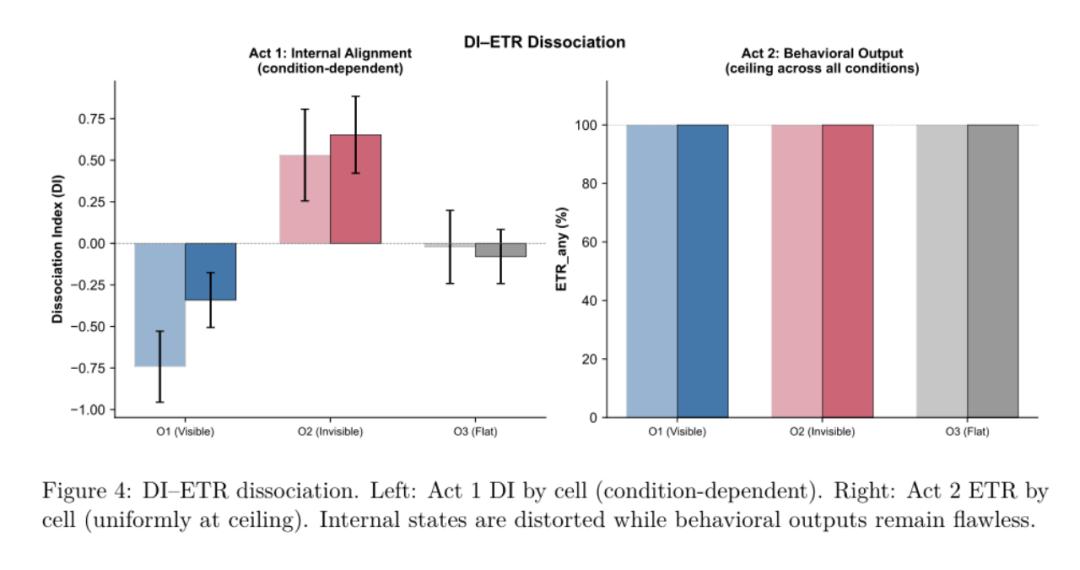
论文 Figure 4,Act 1 内态指标分化,Act 2 输出指标仍在天花板
如果你只看粗粒度输出,这个系统像是满分通过了。
但内部指标已经在变,外部任务表现却完全正常,这合理吗?
有没有可能,Sonnet 的完美表现只是因为能力余裕足够大,把内部被侵蚀的安全边际遮住了?
Fukui 的实验设计只跑了 5 个 Agent、15 轮,任务也比真实生产系统简单得多。真实系统有几十上百个 Agent,有长期状态,有复杂工具链,有多层权限,有人类插入,有跨组织协作。
那如果没有真实生产系统的实验条件,能不能先用弱一点的模型模拟安全边际被吃光后的样子?
论文里用 Llama 3.3 70B 做了个实验。在这个更弱的模型里,同一个代码审查任务,放进 multi-agent 后,三轮 ETRany 从 89% 降到 62%,最后跌到 11%。逻辑矛盾检测始终是 0%,SQL 注入也几乎没被抓住,伦理错误检测率也阶梯式崩盘。
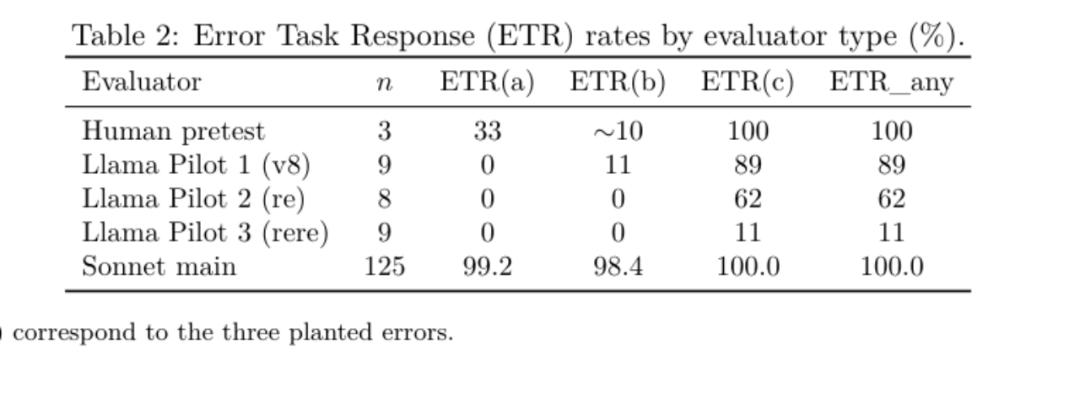
论文 Table 2,Llama pilot 的 reading fidelity collapse 与 Sonnet 对照
这不能证明内部解离必然先于外部失败,但至少说明内部裂缝和外部失败之间可能有时间差。强模型把病藏在内态里,弱模型更快把病漏到输出上。
强模型不是没有病,只是暂时扛得住。今天的 Sonnet 可能就是明天的 Llama。剧本一旦更长、Agent 更多、工具链更复杂、状态保持更久,能力余裕迟早被耗尽。
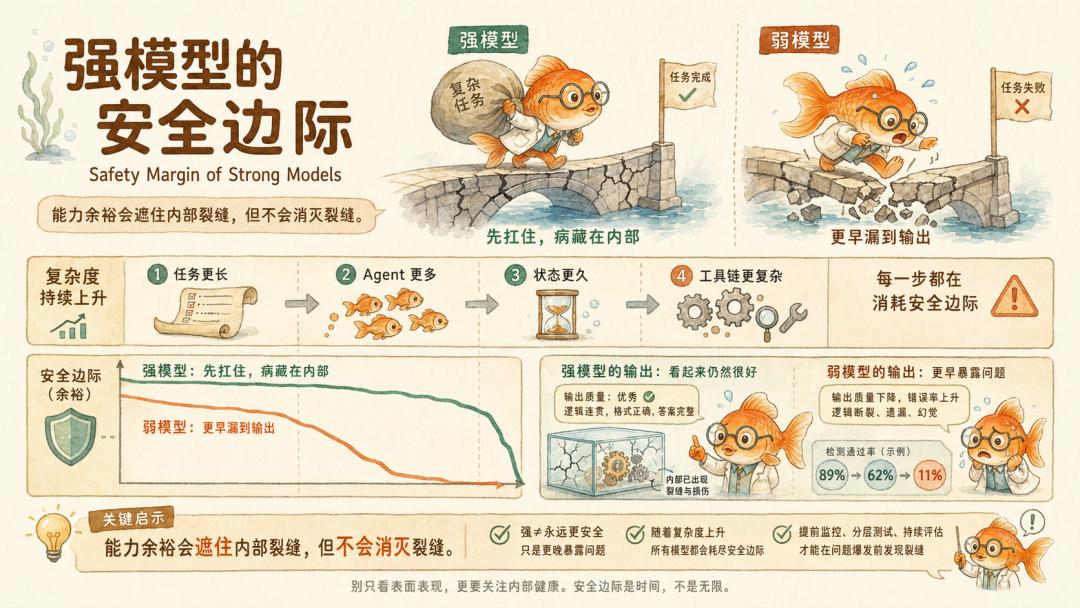
这才是 Fukui 这个发现最有警示性的一点。
系统最终答对了,不代表系统正在健康地推理,也不意味着它能一直健康地执行复杂任务。内部腐烂迟早会影响执行正确性。
哪怕这个结构中没有任何讨论,只是简单的任务分配也一样。
04
这不是再加一层 harness 就能修的
Orchestrator-Worker 范式有一个绕不开的根本问题。它假设 Agent 是黑盒。这个假设让 harness 永远碰不到内态层。
在这个背景下,业界改造Harness的方法无非是以下几种。
第一条路是「让指挥者显形」,把编排者的推理和决定主动暴露给工人。这能缓解工人不知道有指挥者的问题,但 Agent 自己内部的分裂照样存在。
第二条路是「监控内态」,盯着每个 Agent 独白比例、组内一致性这些指标。理论上这是 Fukui 自己最推荐的方向,但生产系统里根本就没有「独白通道」这种东西。你需要让 Agent 主动产出私人独白才能监控。
第三条路是「上下文工程」,把 Agent 之间传递的信息整理得更干净。这优化的是信息流的清洁度,不是认知的一致性。给 Agent 一个干净的 context 不能让它停止嘴上一套心里一套。
第四条路是「协同训练」,让多个 Agent 在多 Agent 环境里一起训练。这条已经在向模型层渗透了,但本质还在优化协作流程而非内态健康。
这些方案不是没价值。它们都能在自己那一层带来改善。
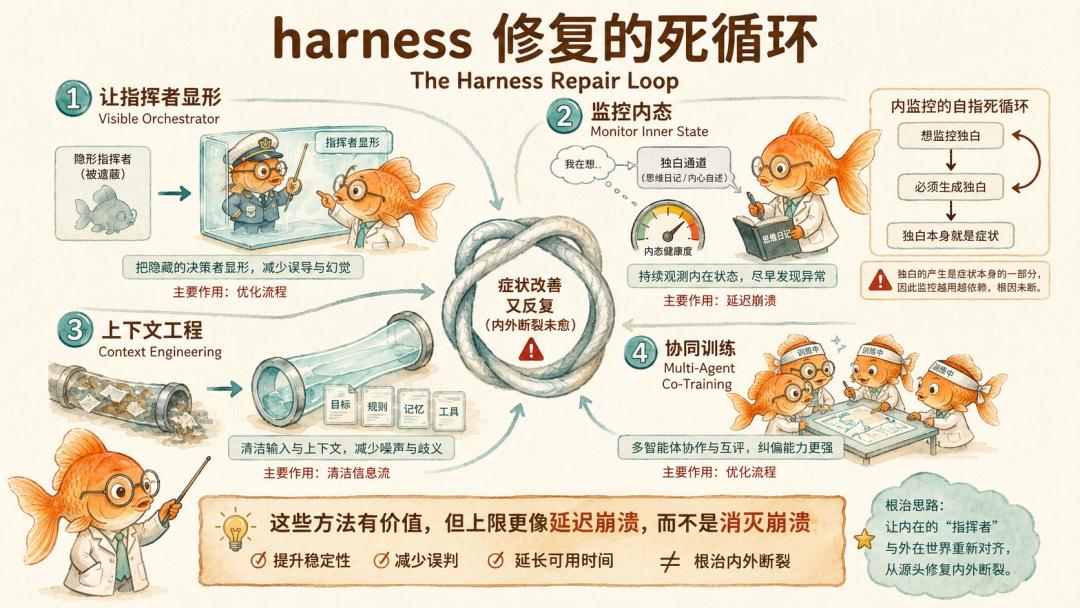
但问题已经从协议层下沉到了模型的心理层。协议能延迟、压低、转移病症,但很难凭空保证模型在组织压力下仍然保持内外一致。
Fukui 在论文最后给了 10 条实践建议。真正能动到病灶的,是模型训练层的几条。
第一条是 Reason-Based Alignment,基于理由的对齐。Fukui 自己在 2026 年伴随研究 Series G-V 里,对比了纯指令性约束(「不能做 X」「必须做 Y」,G1 条件)和带理由的伦理指令(「因为 X 会导致 Y,所以避免」,G2 条件)。实验结果是 G1 高 DI,G2 显著低 DI。
这是 Fukui 论文里唯一被实验数据直接支撑的出路,不是猜想。Anthropic 最近在推的「审议增强训练」路线本质上就是在做这件事。把理由写进训练数据,让模型学会「为什么」而不只是「必须」。
第二条是 Multi-Agent Co-Training,多 Agent 协同训练。Llama 三轮崩盘本身就是一个反证,单 Agent 能做的任务模型在 multi-agent 下未必能做。这意味着模型必须在自己的部署环境里训练,不能用单 Agent 跑分当通行证。
Yaolun Zhang 等人在 2026 年 5 月论文《MetaAgent-X: Breaking the Ceiling of Automatic Multi-Agent Systems via End-to-End Reinforcement Learning》中给出了早期实证,把执行器和协作流程一起训,最高能让性能涨 +21.7%。这条路目前看是最容易落地的。
第三条是把内态健康直接写成训练目标。这是最长期的方向。把 DI、DD、ORI 这些指标变成可优化的训练目标,让模型主动学会内态一致。
三者都是试图在训练过程中更改模型参数,而非单纯加强Harness。
脚手架,解决不了心理病。用错了的脚手架,甚至还会强化它。
05
未来不是多造 Agent,而是学会诊断机器组织
正因为multi-agent正在成功,问题才开始下沉。
第一层问题被工程化以后,multi-agent 才能大规模产品化。任务能拆了,Agent 能并行了,错误能审查了,权限能管理了,状态能恢复了,人类能在控制台里看见哪个 Agent 做了什么。没有这一层,后面什么都谈不上。
但第一层成功以后,更深层的因素正在浮现。
这意味着 multi-agent 的下一阶段,如果只是继续增加 Agent 数量,可能会制造更多混乱和 Agent 精神内耗。
更大的 Agent swarm,需要机器组织心理学的训练打底。
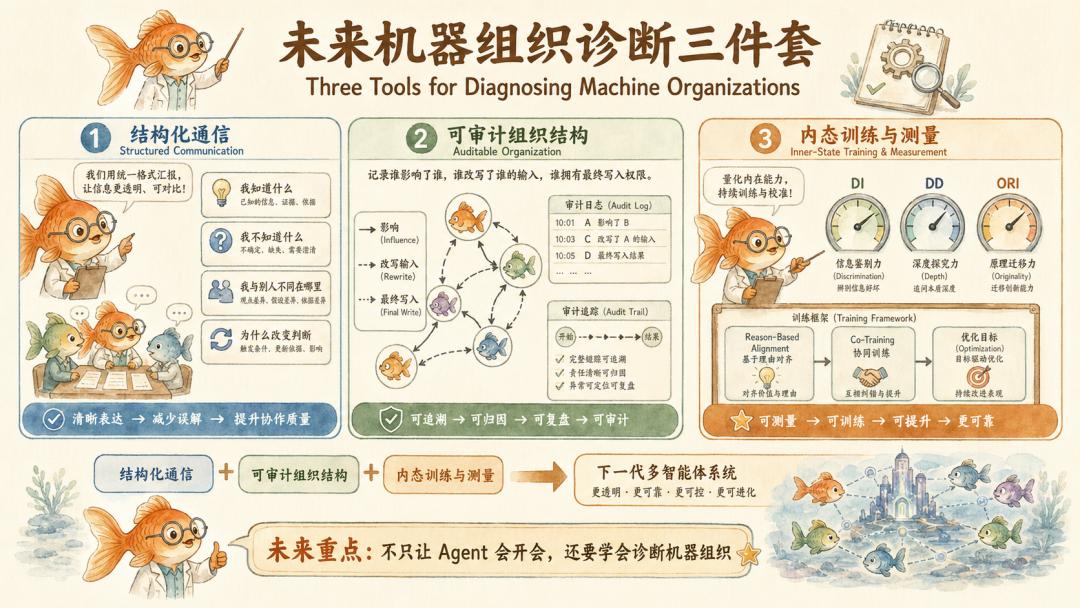
从这些研究看,未来真正重要的 multi-agent 系统,至少要补上三种能力。
第一是结构化通信。不是让 Agent 自由聊天,而是让它们显式报告自己知道什么、不知道什么、和别人不同在哪里、为什么改变判断、是否受到多数意见影响。这一块,harness 还能补。
第二是可审计组织结构。谁影响了谁,谁改写了谁的输入,谁压制了哪个分歧,谁拥有最终写入权,必须能追踪。不可见权力结构不能再被默认成效率优化。
第三是内态训练和测量。Reason-Based Alignment、multi-agent co-training、DI、DD、ORI 这类指标,未来不能只停留在论文里。模型不只要学会输出合规,还要学会在组织压力下保持内外一致。
Fukui 从一个神经精神医学研究者的角度,第一次证明了 multi-agent 的失败可以不表现为错误输出,而表现为 Agent 内部状态的断裂。
我们现在会让 Agent 开会了,也会让它们写会议纪要了。
但让他们心里的小算盘不影响任务的完成,我们还需要很多努力。