-
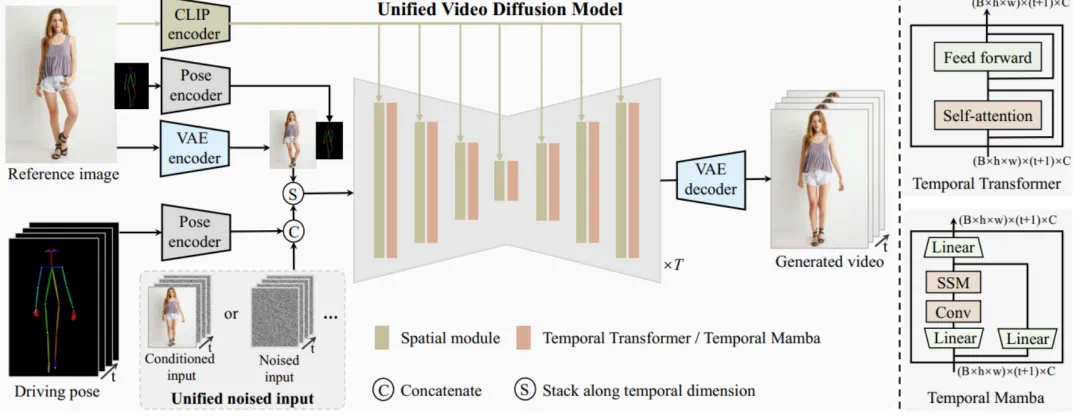
无需额外的参考网络:UniAnimate 框架通过统一的视频扩散模型,消除了对额外参考网络的依赖,降低了训练难度和模型参数的数量。 -
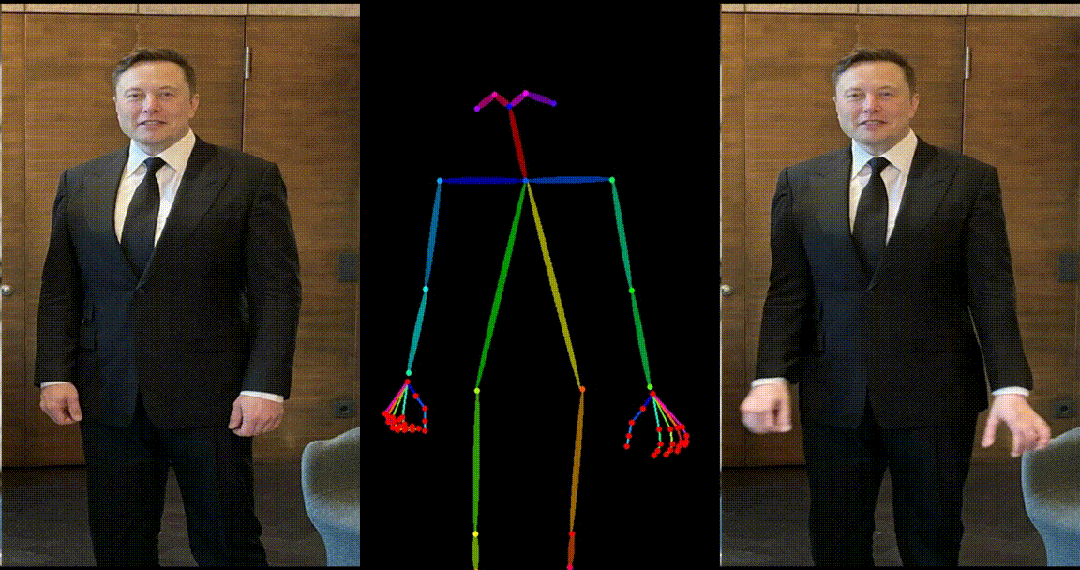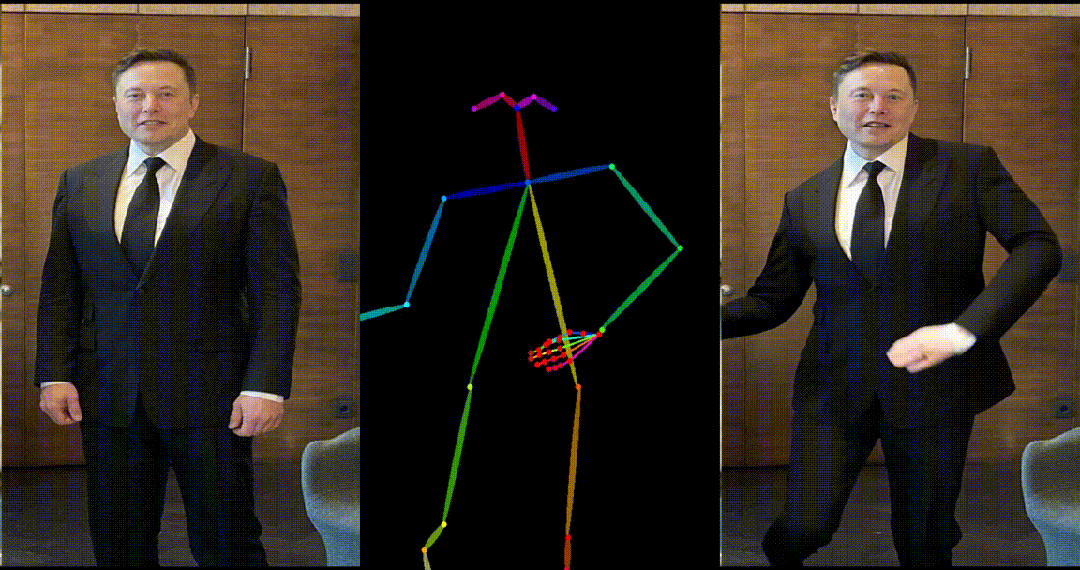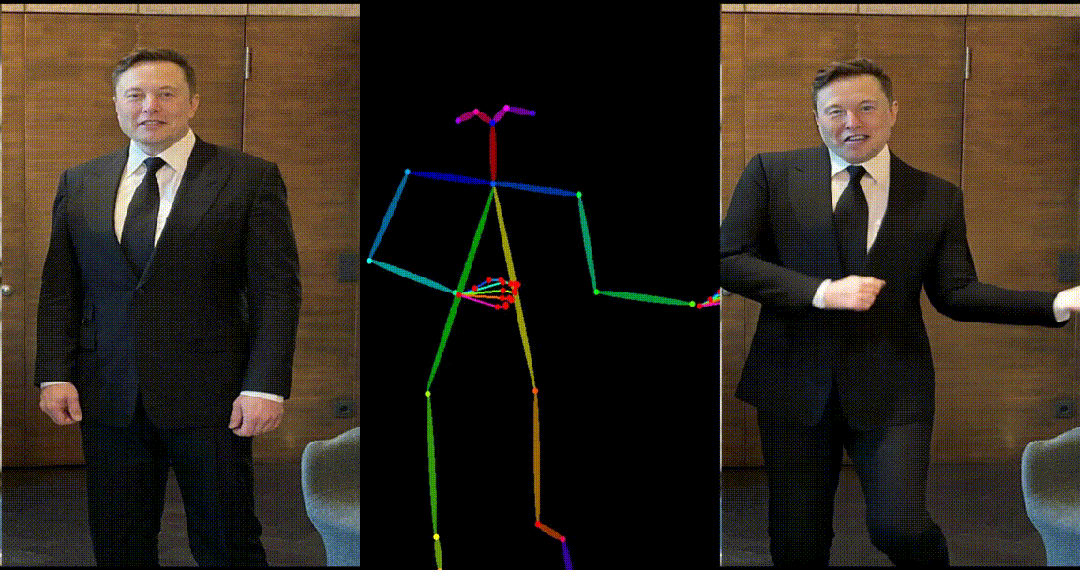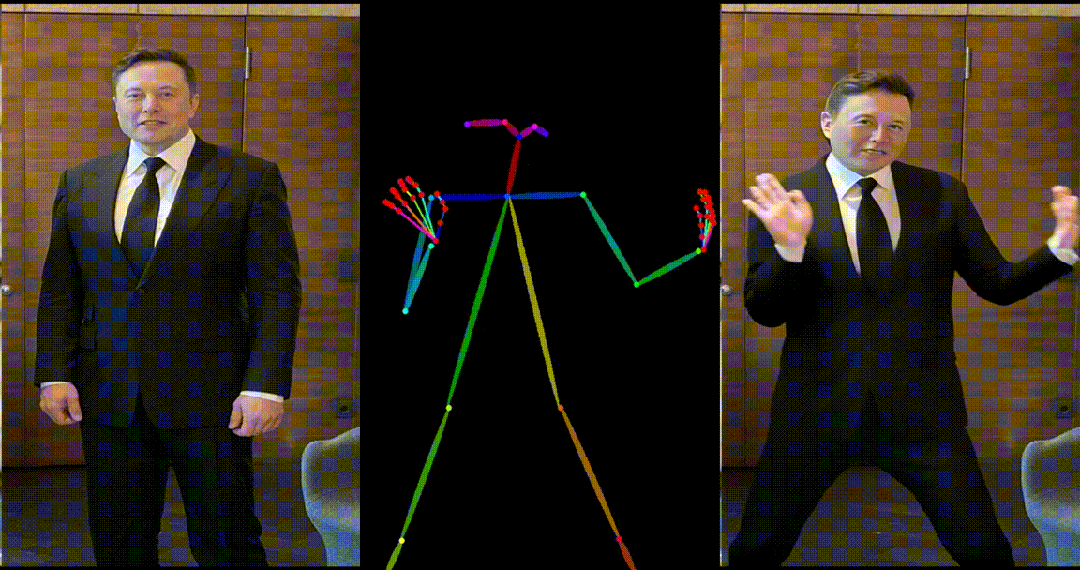
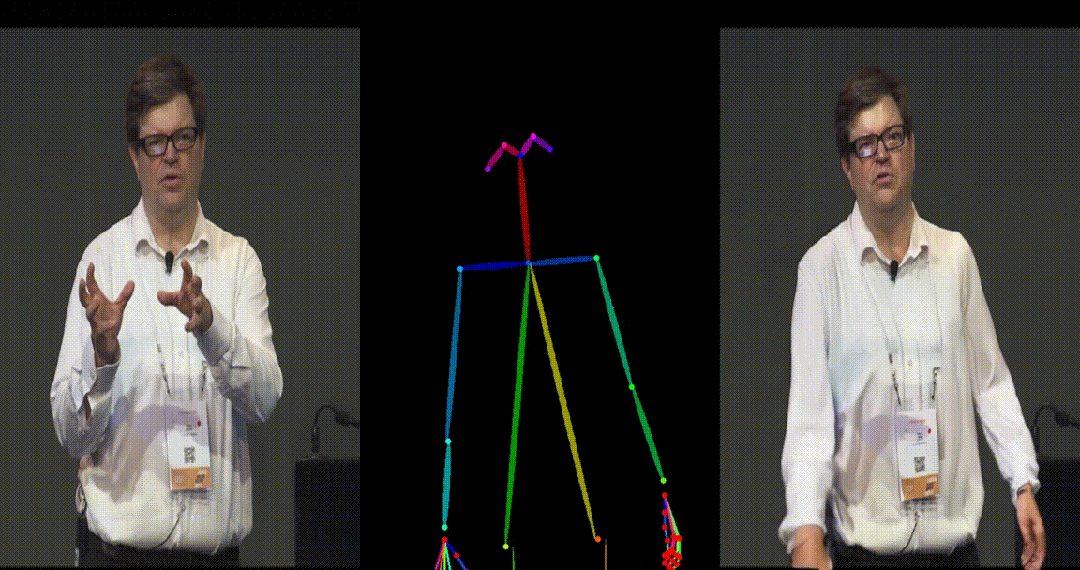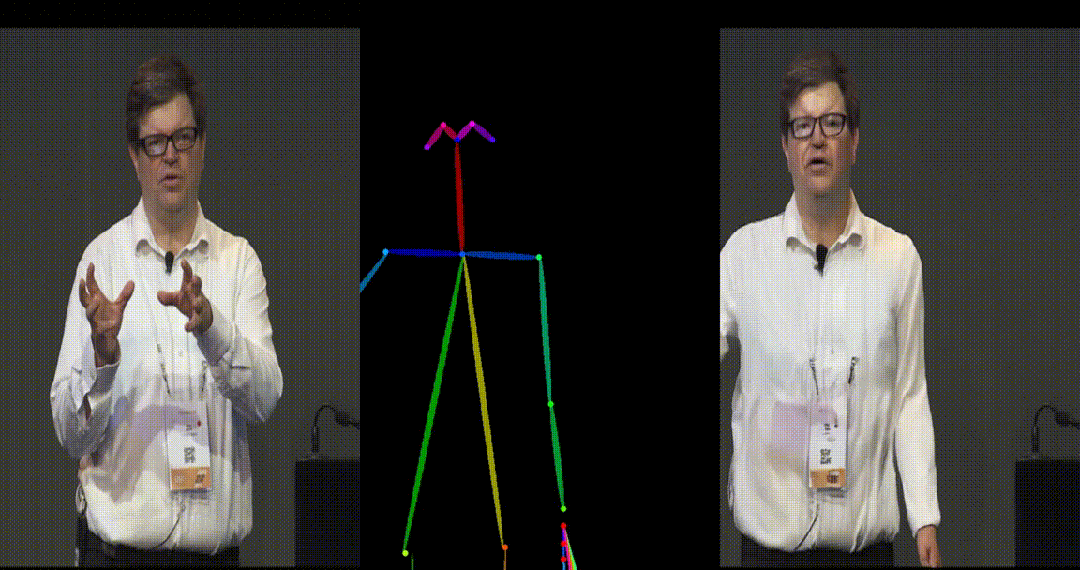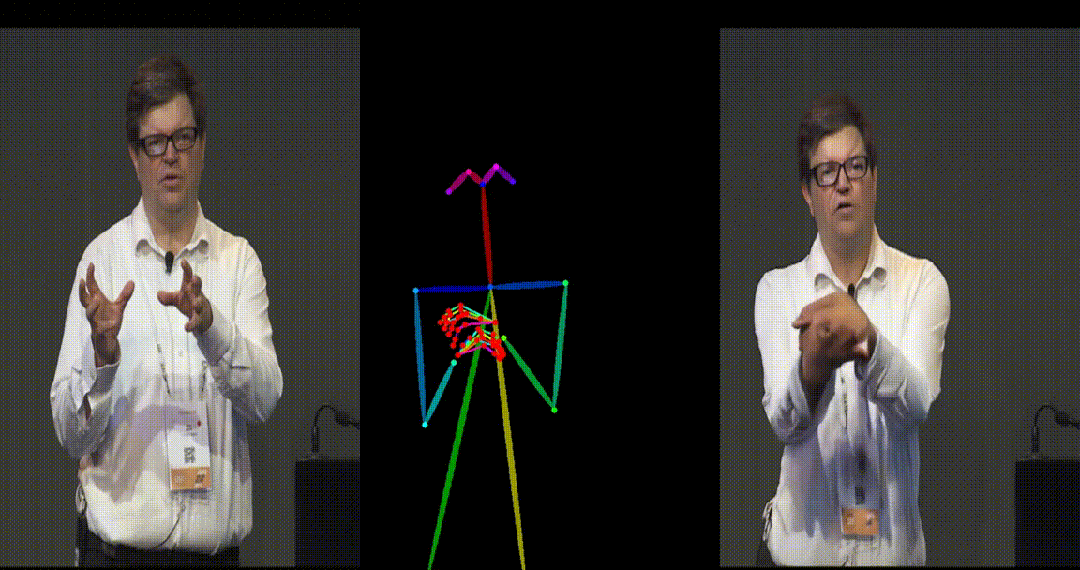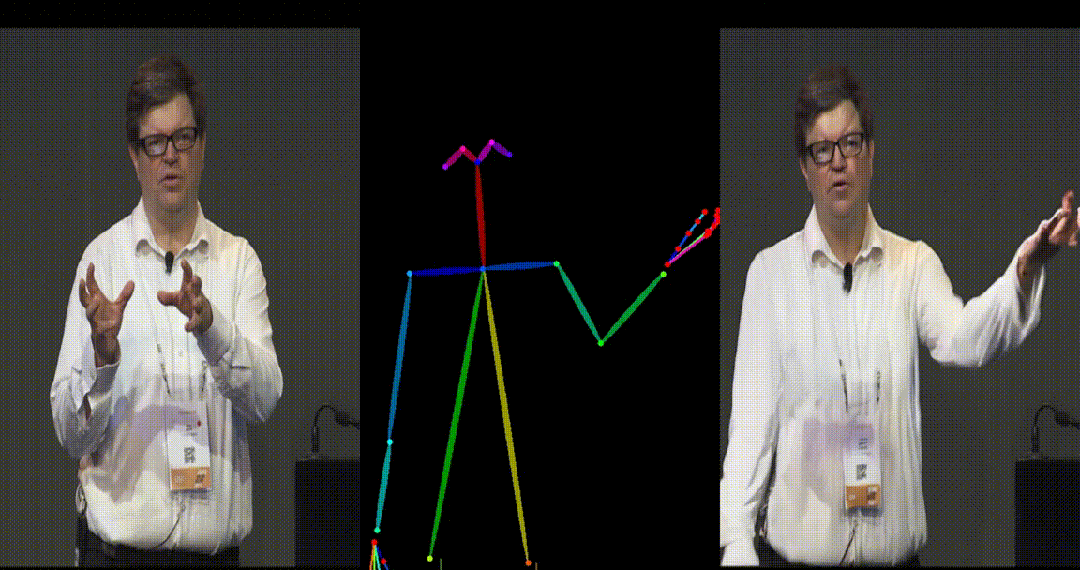
引入了参考图像的姿态图作为额外的参考条件,促进网络学习参考姿态和目标姿态之间的对应关系,实现良好的表观对齐。 -
统一框架内生成长序列视频:通过增加统一的噪声输入,UniAnimate 能够在一个框架内生成长时间的视频,不再受到传统方法的时间限制。 -
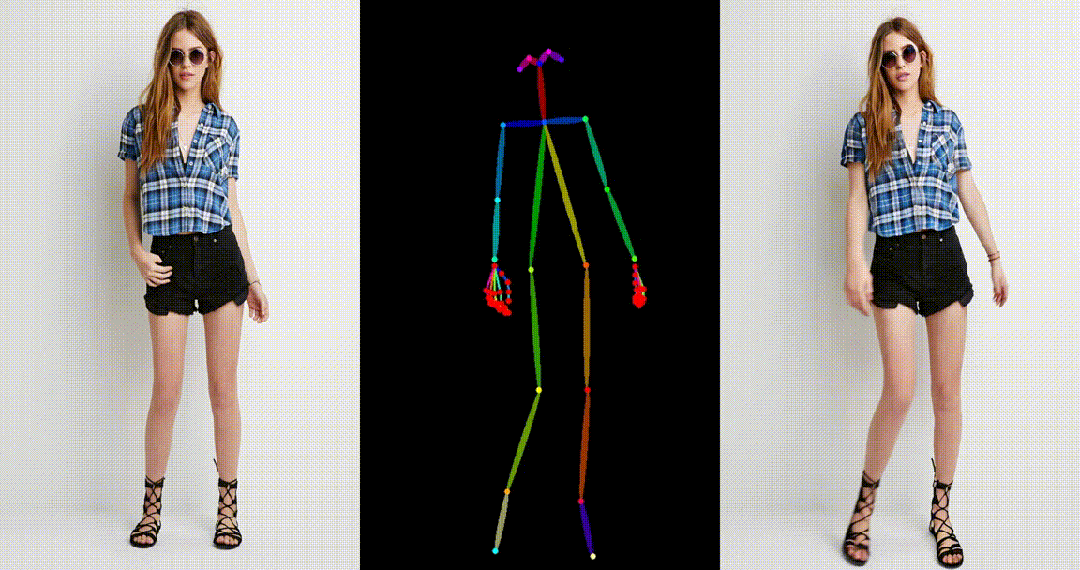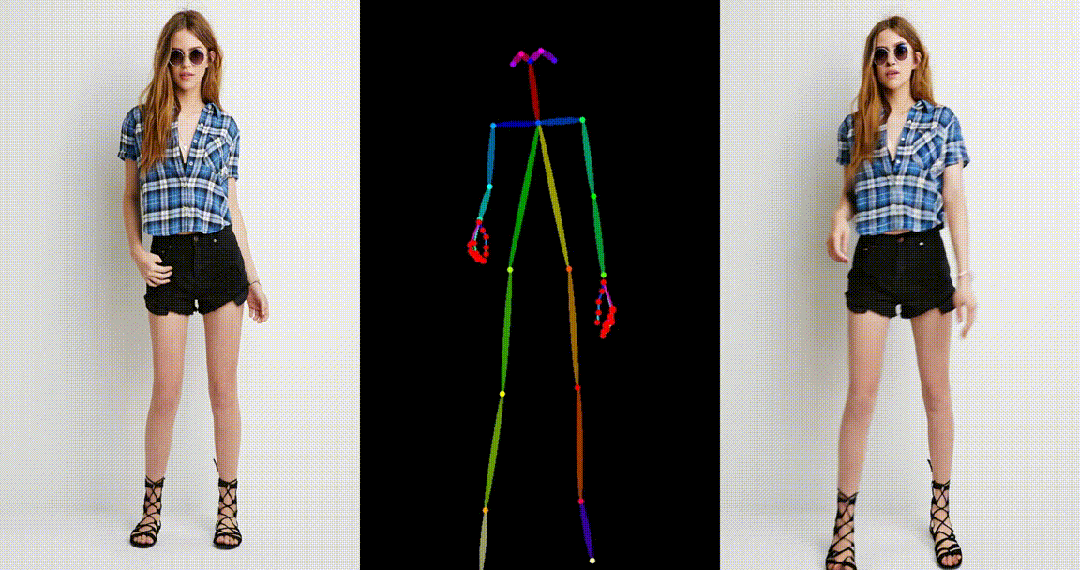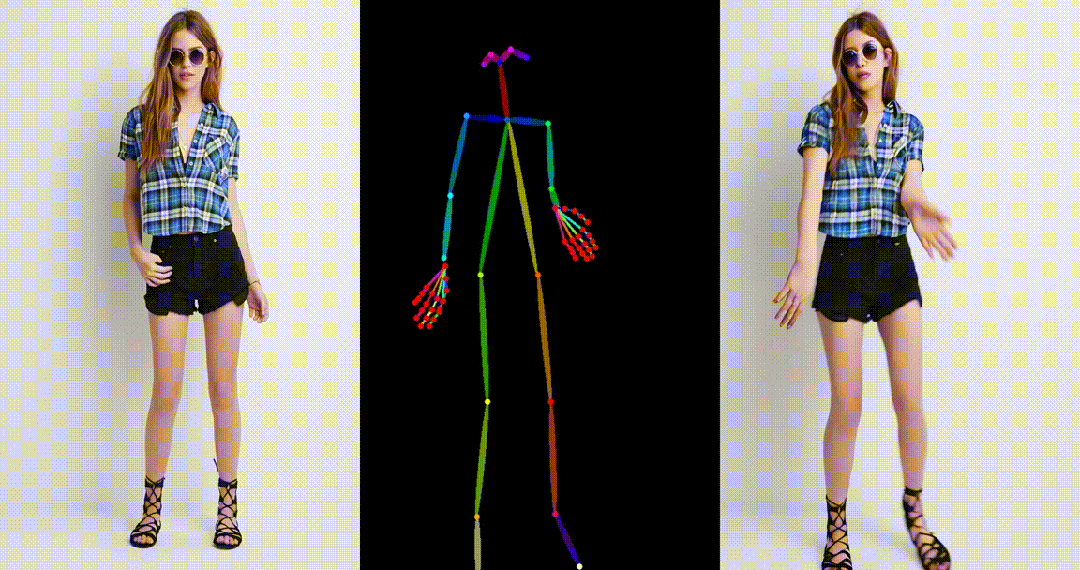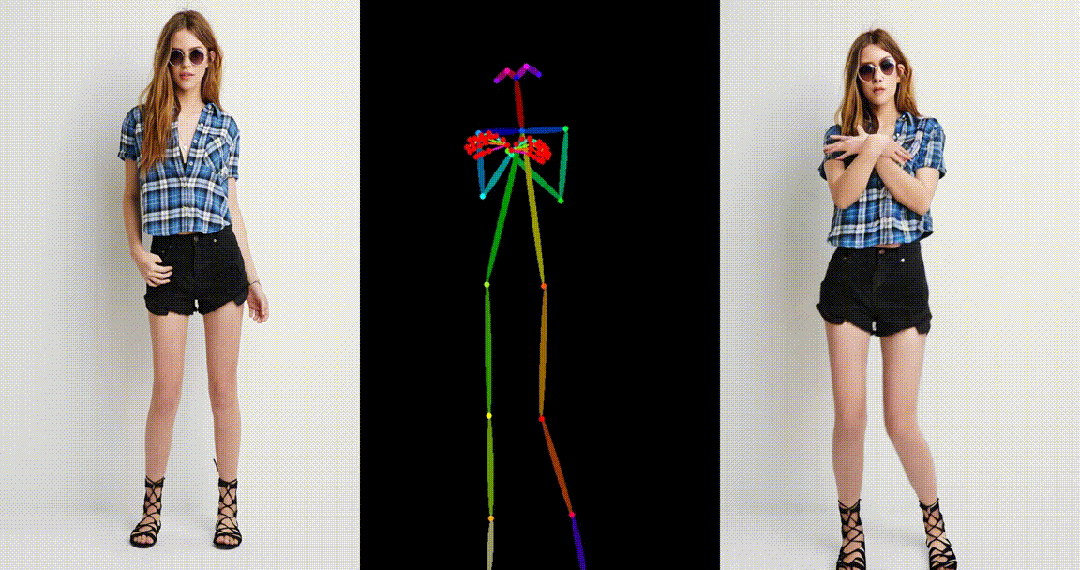
具备高度一致性:UniAnimate 框架通过迭代利用第一帧作为条件生成后续帧的策略,保证了生成视频的平滑过渡效果,使得视频在外观上更加一致和连贯。这一策略也使得用户可以生成多个视频片段,并选取生成结果好的片段的最后一帧作为下一个生成片段的第一帧,方便了用户与模型交互和按需调整生成结果。而利用之前时序重合的滑动窗口策略生成长视频,则无法进行分段选择,因为每一段视频在每一步扩散过程中都相互耦合。





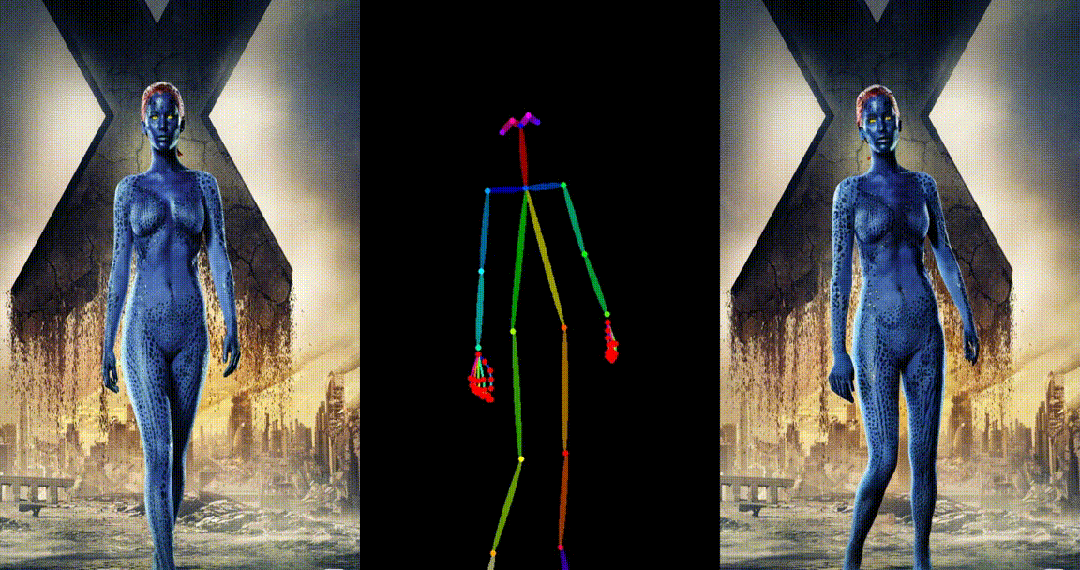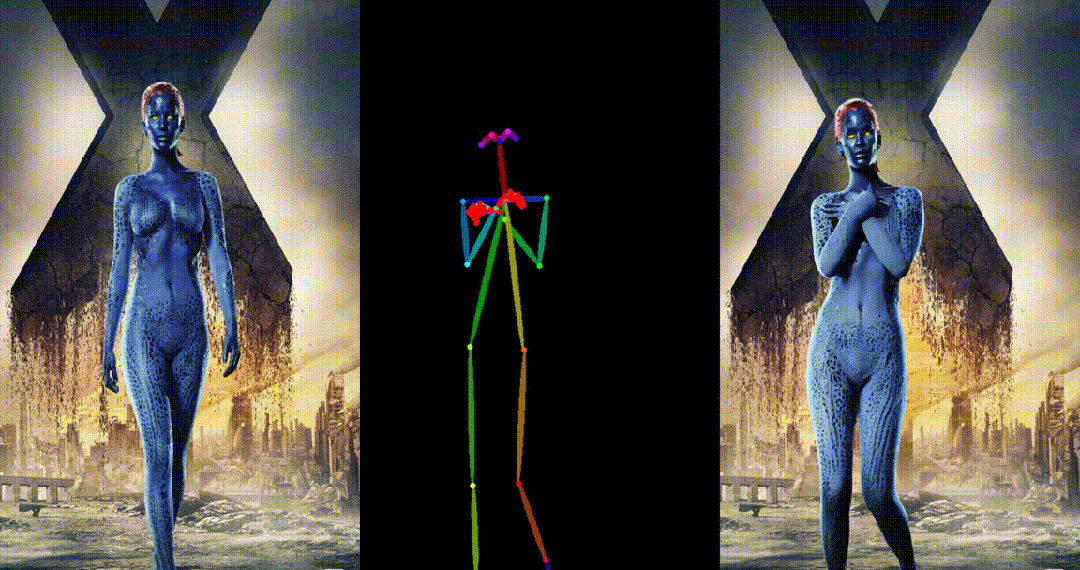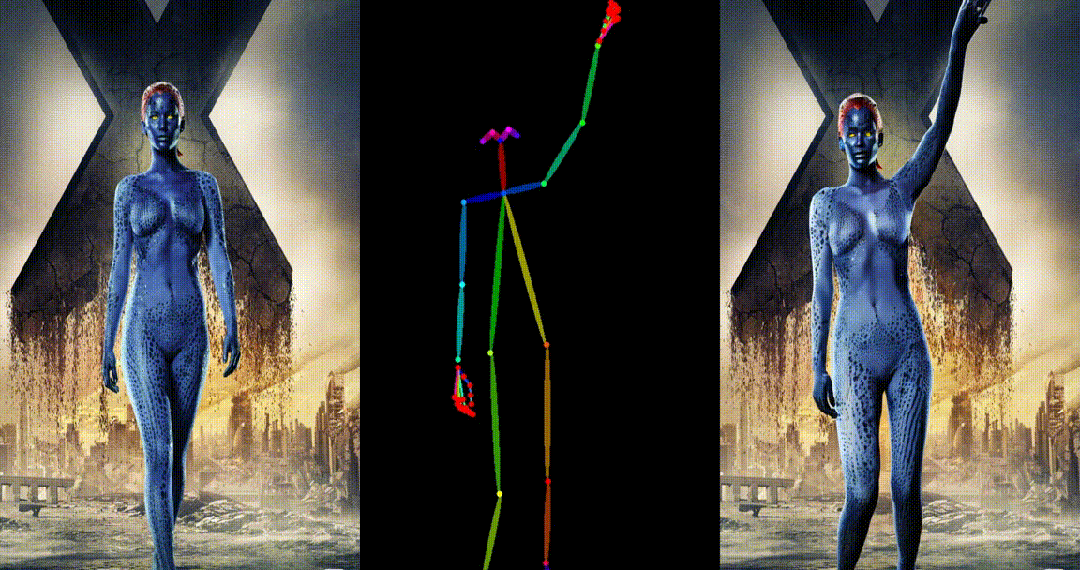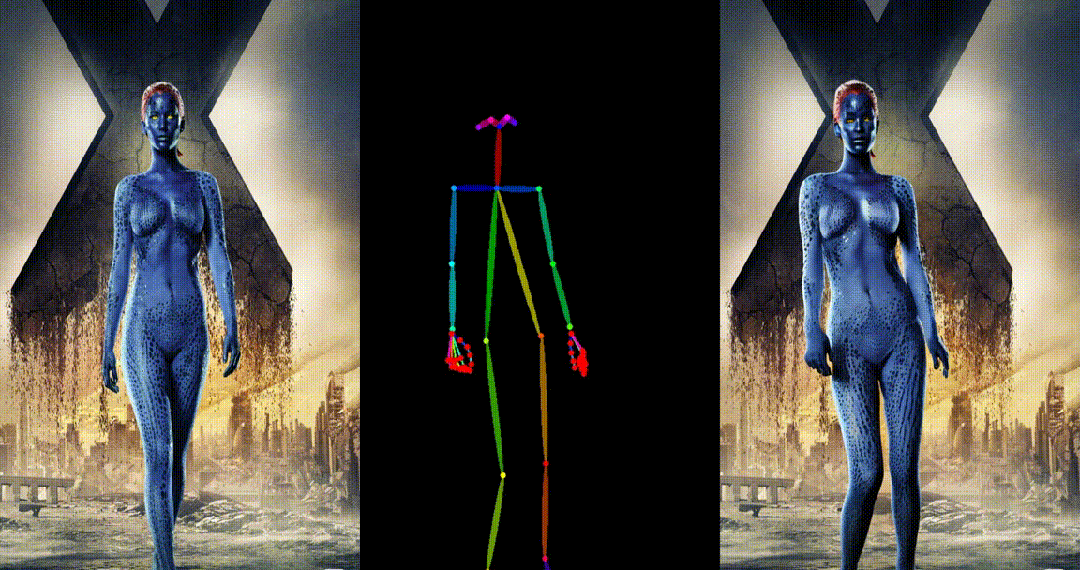



© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
AI导航网,收集全网最新最全资讯,关注我,AI世界不迷路。