
集群部署 本地运行
四台十万元的 Mac Studio 并联在一起,就能部署一套价值上百亿人民币的超大规模 AI 模型?
听上去像是天方夜谭,但这的确就是 Apple Silicon 给苹果的自信。
前几个月,爱范儿就曾经报道过来自牛津大学的 Alex Cheema 与 Seth Howes 共同创建的 Exo Labs 公司,借助自己开发的分布式模型调度平台,将两台 Mac Studio 串联起来实现本地运行百亿级参数模型的事例:
延伸阅读:俩人拼出 40 万的 Mac Studio「缝合怪」,双开满血 DeepSeek 不在话下

苹果显然也注意到了 Exo Labs 的成果。
在最新的 macOS 26.2 Beta 中,苹果为 macOS 的 AI 能力进行了一些极具针对性的加强,瞄准的方向正是 Exo Labs 所展现的—— Mac 集群化部署。
简单来说,在最新版的 macOS 26.2 Developer Beta 中,苹果做出了两项重大改进:
苹果开发的开源阵列框架 MLX 也可以调用 M5 处理器的神经网络加速器了
Mac 集群可以使用一种新的基于雷雳 5 协议的更高速传输通道了
神经网络加速器「普惠万家」
在刚刚更新的 14 寸 MacBook Pro 中,苹果除了给 M5 处理器用上最新的 3nm N3P 工艺之外,还在 GPU 的每个核上都加入了一个神经网络加速器,实现了跑本地模型「10 核赶上 24 核」的效果:

而 macOS 26.2 中更新的 MLX 框架,则进一步拓展了 M5 上神经网络加速器的使用场景:现在不仅「亲儿子」Apple Intelligence 可以用,借助 MLX 部署的第三方 AI 模型也能用。
MLX 是一套苹果机器学习团队开发的、专为 Apple Silicon 特化的「开源阵列框架」,它的主要作用就是让开发者在 macOS 程序中部署和微调自带的 AI 模型,并实现自带模型的「纯本地运行」。

图|MLX 官网
这样一来,开发者在自己的 app 里部署模型,就可以用 M5 处理器的神经网络加速器提高响应速度了。同时还保留着自己(或者让用户)对模型进行微调的能力、灵活性比 Apple Intelligence 更高——
直观地说,就是利好那些目前用不上 Apple Intelligence 的 Mac 用户,比如我们。

况且,在 MLX 借助神经网络加速器「如虎添翼」之后,Mac 的整体 AI 能力还会得到更进一步的提升。
而这也为 macOS 26.2 Beta 中带来的另一项 AI 升级,打下了坚实的基础。
正如前面提到的,Exo Labs 的「Mac 集群」方案,从最初勉强带动 405B 的 Lllama,到最后顺跑 671B 的 DeepSeek V3,借助他们设计的动态负载分配规则,几乎将 Mac 的本地 AI 性能推向了电脑的硬件上限。
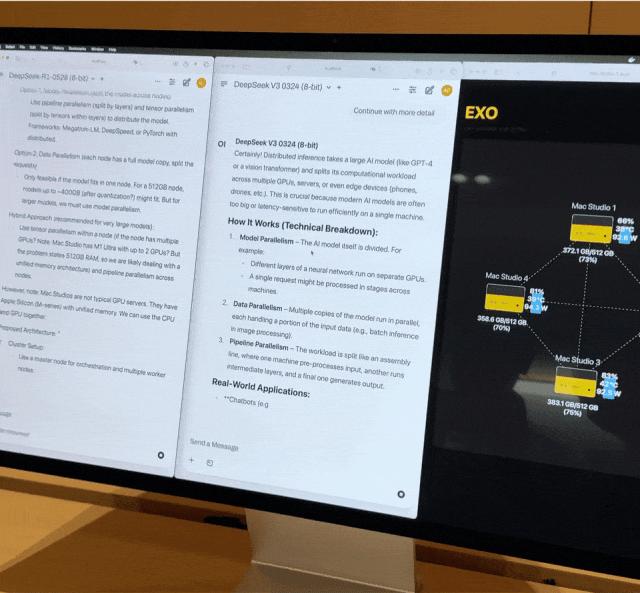
而 macOS 26.2 Beta 中所做的,则是进一步提升——或者说解锁了—— Mac 的能力上限,给类似 Exo Labs 的本地 AI 工具以更广阔的发挥空间。
那苹果究竟做了什么,才能让 Mac 在不改变硬件的前提下,凭空多出来一部分本地 AI 性能呢?
答案是,这个听起来和「下载免费内存」一样的神奇操作,实际上是通过优化 Mac 集群之间的数据传输方式实现的。

图|Apple Insider
雷雳 5 的一百种用法
在之前版本的 Exo Labs 中,进行物理连接、建立拓扑网络、汇总统一内存池和进行负载分配的工作,都是借助 Mac Studio 之间的雷雳 5 信道完成的。
然而尽管雷雳 5 的纸面规格很高,但 macOS 却只能通过古老的 TCP-IP 方式连接各台 Mac。

图|Jon Deaton
这就带来了一个问题:TCP-IP 并不是专门为 AI 集群优化的协议。尤其是「并行 AI 计算」这种对带宽和延迟要求极高的场景,TCP-IP 的「节点间延迟」还会被进一步放大。
而 macOS 在设备互联的时候使用 TCP-IP,进一步导致了 Exo V2 哪怕可以借助 2TB 统一内存加载一个巨大的模型,却只能使用相对低效的「管线并行」(pipeline parallel)方式将负载分配到四块处理器上——
相当于这四台 Mac Studio 的集群,坐拥 2TB 内存和 240 个 GPU 核心,却只能等一个节点上的 Mac Studio 处理完,才能传给下一个节点的 Mac Studio 做进一步处理,任务分配效率并没有达到最优解。

图|X @exolabs
现在,这个协议导致的瓶颈终于得到了解决——苹果开发了一套新的以雷雳 5 为基础的 macOS 连接协议,在原本 TCP-IP 的基础上,为 Mac 提供了一种大幅改进传输延迟的新的「建群」方案。
换句话说,现在仅凭 Mac 自带的雷雳 5 接口和控制器,就可以实现超低延迟的大带宽、低延迟交换。放在 Mac 集群里,相当于是让其中的每块 M3 Ultra 处理器在任意时间都能直接调度全部 2TB 的统一内存池。

图|FiberMall
值得注意的是:虽然苹果这套新方案的效果非常像 RDMA(远程内存直接访问),但并不需要 RDMA 那样设置以太网卡或者光模块,而是完全依赖现有的雷雳 5 硬件实现的。
这样一来,原本 Exo V2 碰到的节点间通讯延迟(inter-node latency)问题就得到了极大的优化,也让 Exo Labs 得以在最新版本的软件 Exo V3 里,实现了 Mac 集群里的「张量并行」(tensor parallel)分配。
相比「TCP-IP + 管线并行」的组合,macOS 26.2 Beta 的「雷雳 5 + 张量并行」方案,可以极大优化负载的分配效率、让四台 Mac Studio 互相协调和分配任务的时间,从而进一步提升每秒钟生成的 token 数。

甚至借助新的雷雳 5 传输方案,Exo V3 还为构建集群的方式提供了灵活选择。
现在不仅可以在不同型号的 M 系列处理器之间搭建集群,用户还可以自行选择让各个节点的 Mac 用 TCP-IP 或者雷雳 5、管线并行还是张量并行,以实现各个场景的利用率最大化。
这种同时来自苹果第一方和 Exo Labs 第三方的提升,是切实有效的。
在最新版本的 Exo V3 中,我们甚至看到了在四台顶配 M3 Ultra Mac Studio 集群上,纯本地运行的 Kimi-K2-Thinking,一个量化后约 800GB 内存的一万亿参数大语言模型。最终的输出速度达到了约 25 token/秒。
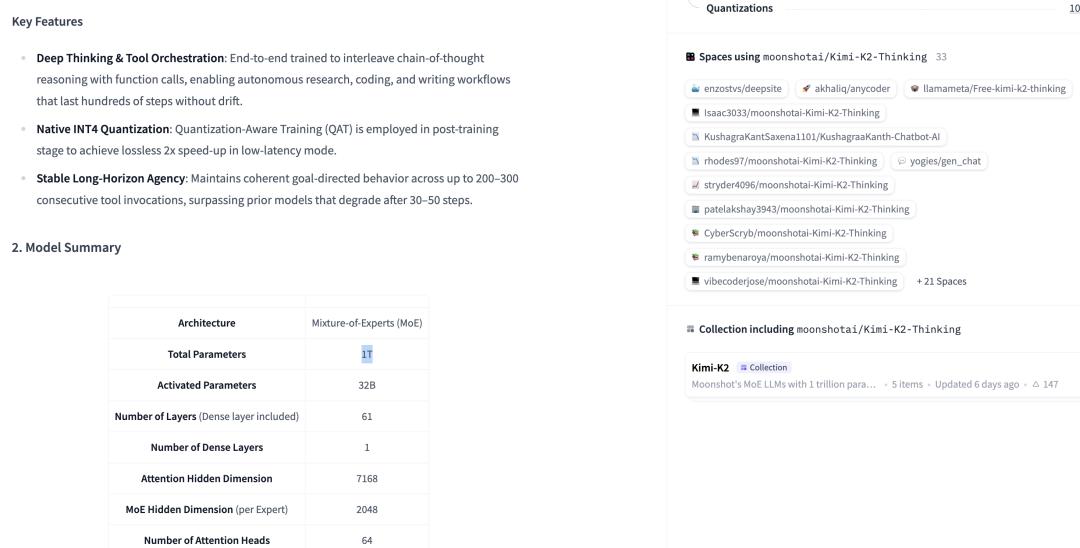
当然,Kimi-K2-Thinking 是一个混合专家(Mixture-of-Experts, MoE)架构模型,生成每个 token 时并不需要调动全部一万亿的参数,实际部署的压力没有参数量那么恐怖。
但这样规模的 LLM 能够仅靠四台 Mac 电脑就带动,依然是一件非常了不起的事情。
根据估算,目前的主流闭源模型如 Gemini 1.5 和 GPT-4 等等,也都是 1~2 万亿参数的 MoE 架构,换个角度想想——
花四十万或者八十万,组一个 Mac Studio 的大集群,你就可以自己在家跑一个独享的 Gemini 或者 GPT 了,并且没有任何限制、可以微调成你自己想要的任何样子。
Mac 的 AI 价值,其实在商业
说到这里,macOS 26.2 Beta 主要是在 Mac 的 AI 能力上进行了一次「提升式」更新。
一边让第三方模型能用上 M5 芯片的新特性,一边让 Mac 组集群的效率更高,似乎不如老黄搬出 DGX Spark 那么让人兴奋——

图|Tom’s Hardware
然而事实不是这样的。
苹果借由 macOS 26.2 强化 Mac 的 AI 能力,实际上是和曾经自研处理器那样,正在看不见的地方悄悄努力、为最终的生态建设积攒能量。
如前面所说,四台 Mac Studio 用 Exo V3 组成集群,就能本地运行近似 GPT-4 规模的巨型模型,乍看上去好像不是个很划算的买卖。
毕竟能花四十万人民币买 Mac 的人,一般都有比本地跑模型更重要的事情要做。
但对个人没有用,不代表对企业没有用。苹果暗自加强 Mac 的集群 AI 性能,正是瞄准了目前相对缺乏关注、规模效应没起来,但潜在用户极多的「企业本地部署」市场。

图|Digitimes
出于商业信息保密和细分化需求的考虑,极少有企业会直接选择订阅 AI 巨头的在线服务、然后把业务内容、财务报表或者研发数据丢上去跑分析——
对于这些高敏感数据,企业的 AI 功能需求往往是必须「纯本地化」的。
然而,一旦要选择本地部署,很多企业用户就发现自己会迅速陷入了一个「水多加面、面多加水」的过程:
买了显卡要放服务器,买了服务器要放机房,建了机房要配套地皮通风电力网络基础设施……到了那个阶段,买显卡甚至可能是总成本里最不起眼的那一块。

图|Data Center Knowledge
这种时候,集成了 CPU、GPU、共用内存、散热和供电,并且集群能力完全不输 DIY 主机的 Mac Studio,就显得极为突出了——
不仅 Mac 集群需要的空间和散热规模比散装服务器低了几个量级,成本最大的用电更是接近腰斩(前面运行 Kimi-K2-Thinking 时的总功耗仅为 500W 左右)。
用一堆 Mac Studio 搭一个机房虽然也得上百万,但以三五年的跨度来计算,它的总拥有成本(Total Cost of Ownership, TCO)比起散装服务器,能省出好几个这样的机房。

图|AppleInsider
同时,它还保留着所有纯本地运行 AI 模型的优势:数据私密性、全方位的微调能力、动态负载分配(比如同时跑一个超大模型或者三四个小模型)等等。
对于企业部署场景来说,其中的每一项可能都要比「绝对性能」更重要。
无心插柳柳成荫
用 Mac 搭集群、本地跑 AI 的有趣之处在于:这不像是苹果深思熟虑的产品战略,倒像是一个双向奔赴的意外。
最初,在苹果设计 Apple Silicon 时,它追求的是统一架构、电脑能效比、跨端体验的一致性,并没有考虑 AI 模型会在几年后成为行业的主题。

然而运行本地模型、隐私数据管控、硬件成本控制、数据中心节能——这些五年前还怎么不明显的需求,在 2025 年却逐渐变成了中小规模企业、工作室和开发者对 AI 业务的核心诉求。

正是这两者的碰撞,造就了今天 Mac 作为「本地 AI 工作站」的无法替代的价值。
此外,macOS 26.2 Beta 是一次纯软件更新,后续所有支持雷雳 5 的 Mac 机型都能在「搭集群」的场景中受益。
那些买 Mac Studio 的用户,并不是「十万元买了台艺术电脑」,反而会突然发现自己的设备价值倍增——
这台当初买来剪视频、做设计的工作站,现在可以运行万亿参数的大模型了。

图|AppleInsider
虽然这像是一次意外,但恰恰也是技术储备的意义所在——技术的价值,有时会在意想不到的地方显现。
此前苹果选择统一内存架构,是为了让 Mac 的体验和 iPhone 保持一致;推雷雳 5,是为了支持更高规格的音画输出;在每个 GPU 核心里塞神经网络加速器,是为了 Apple Intelligence。

起初,没有人想到这些策略会在 AI 时代产生如此的化学反应。
但当 AI 模型的行业化、规模化应用真正爆发时,这些「无心」的技术积累,恰好帮助 Mac 成为了最合适的解决方案之一。
无心插柳柳成荫,这可能是对 Mac AI 能力最贴切的形容。